

AI语音助手:揭露手机“听懂”你说话的奥秘
清晨,你刚睁开眼,随口一句:“小爱同学,今天天气怎么样?”话音刚落,“小爱同学”立刻回应:“今天晴,25度,适合出门。”这看似简单的对话背后,其实藏着一场精密的“人机对话”工程。今天,就让我们一起揭开AI语音助手的奥秘——你的声音,是如何被手机“听懂”的?
|
|

一、从“声音”到“信号”:音频特征的提取
当你说话时,声波通过空气传到手机麦克风,变成一串连续起伏的电信号。但对计算机来说,这还只是一堆杂乱无章的“波浪线”,无法直接理解。于是,系统首先要做的,是将这段连续的数字信号“切片”成帧,并从中“提取”出机器能处理的数字特征。这个过程就像把一段交响乐拆解成每个乐器的音高、节奏和强弱。
具体怎么做?首先,系统会把连续语音切成20–30毫秒的小片段(称为“帧”),因为在这极短的时间内,语音可近似看作稳定状态。接着,通过数学工具(如傅里叶变换)将每帧声音从“时间域”转换到“频率域”,得到一张频谱图——你可以把它想象成声音的“指纹”。最后,提取梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,简称MFCC,是一种广泛应用于语音信号处理和语音识别领域的声学特征提取方法)。这个名词听起来很专业,其实原理很简单:它通过模拟人耳对频率的感知特性,对频谱进行滤波和压缩,最终提取出一组最能代表该帧声音特征的系数。
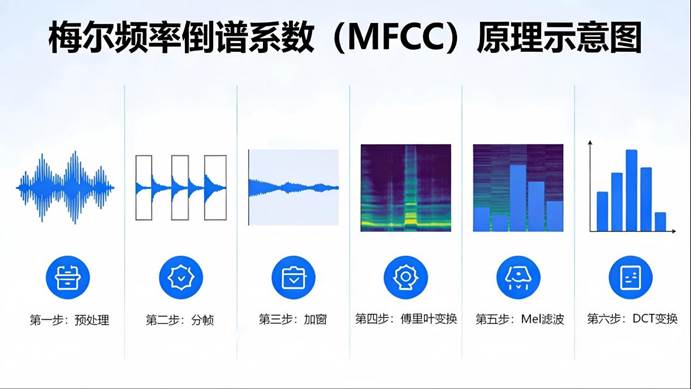
这一步的目标只有一个:让手机“听清”你说的是什么音。
|
|

二、从“音”到“字”:声学模型的魔法
有了声音的“数字指纹”,下一步就是确定这些声音对应哪些音节或汉字?这就轮到声学模型登场了。你可以把它想象成一个“声音翻译官”,专门负责把声音特征翻译成可能的发音单元。
深度学习为声学模型带来了质变,早期深度模型如LSTM显著提升了性能,而当前基于Transformer架构的模型(如Conformer),能像人类一样“记住上下文”。比如你说“我要去银行”,模型不仅听当前音,还会结合前后音判断“行”是“háng”还是“xíng”。更聪明的是,现代系统采用端到端训练——不再分步处理,而是直接输入音频,输出文字。其中,关键技术:连接时序分类(Connectionist Temporal Classification,简称 CTC,是一种专为输入与输出序列长度不一致且未对齐的序列建模任务设计的神经网络训练方法)能自动对齐长短不一的声音和文字,哪怕你说话快慢不一,也能准确识别。
三、从“字”到“意”:语言模型来纠错
但光靠声音还不够。比如你说了“我想吃苹果”,声学模型可能输出“我想吃 Ping Guo”——但它不确定是水果“苹果”,还是手机“Apple”。这时,语言模型就发挥作用了。它像一位“语文老师”,根据日常语言习惯判断哪种组合更合理。
现在的AI则用神经网络语言模型,能理解更长的上下文。例如,在“下载最新___”这句话中,模型会高概率预测“软件”,而不是“西瓜”。正是语言模型的存在,让语音识别不仅能“听对音”,还能“说对话”。
四、最终决策:解码器做出“最优选择”
前面几步会产生多个可能的候选结果。比如你说“打开空调”,系统可能同时考虑:“打开空调”“大开空跳”……
谁来拍板?解码器。它像一位“裁判”,综合声学模型的“发音可信度”和语言模型的“语义合理性”,计算出整体得分最高的那句话。常用策略如Beam Search(保留几个最有希望的候选路径逐步扩展),在速度与准确之间取得平衡。整个过程通常在不到一秒内完成——比你眨一次眼还快。
今天的AI语音助手,早已超越单纯“语音转文字”。它们还能:
1. 理解意图:你说“帮我订明天早上的闹钟”,它知道要设置时间;
2. 多轮对话:你问“北京天气?”再问“那上海呢?”,它能关联上下文;
3. 个性化学习:熟悉你的口音、常用词,越用越准。
背后支撑这一切的,是大模型、大数据及自监督学习等技术的融合。
在重庆这座8D魔幻城市,AI语音助手早已不只是“普通话翻译官”。当你驾车穿行于洪崖洞的盘旋匝道,只需一句“导航到磁器口古镇”,语音助手不仅能精准识别带点“椒盐味”的普通话,还能结合实时路况,避开嘉陵江大桥的拥堵路段,推荐你走千厮门大桥看江景。这背后,是语音系统通过本地化训练数据,学习了大量重庆方言词汇、地名发音和复杂路网特征。甚至当你问“附近有啥子好吃的?”,它能推荐你去解放碑的“十八梯邓凳面”,让科技不仅听懂你的声音,更读懂这座城市的烟火气。